【Amplify】 APIGatewayのAuthorizerにCognitoを指定する
概要
AmplifyでOverride機能を利用してAPIGatewayのAuthorizerにCognitoを指定する方法をご紹介します。
課題
2022/3/10現在、Amplify CLIでは、APIGatewayのAuthorizerにIAMしか利用できません。AWSのコンソールからCognitoを指定したとしても更新した際にテンプレートで上書きされてしまい、設定したAuthorizerの情報が消えてしまいます。 そのため、Override機能を利用してAPIのCFnテンプレートを修正する必要があります。
手順
APIGateway・Cognitoのoverride.ts作成
CLIで以下のコマンドを実行し、override.tsを作成します
amplify override auth amplify override api
override.tsの編集
Authでは、CognitoユーザープールのIDをエクスポートします。 エクスポート名は重複が許されないため、環境名を取得してユニークにしています。しかし、デフォルトではバグで取得できないため迂回しています。詳細は以下の記事をご覧ください。 Amplifyのoverride.tsで環境名を取得する
import { AmplifyAuthCognitoStackTemplate } from '@aws-amplify/cli-extensibility-helper';
export function override(resources: AmplifyAuthCognitoStackTemplate) {
// override.tsでenv名を参照することはできない(バグ)。そのためamplify-metaからenv名を取得している
// https://github.com/aws-amplify/amplify-cli/issues/9063
const amplify_meta_json = require('amplify-meta.json')
const env_name = amplify_meta_json.providers.awscloudformation.StackName.split("-").slice(-2, -1).pop()
const export_user_pool_id = {
description: "cognito user pool id",
value: resources.userPool.ref,
exportName: `exportUserPoolId-${env_name}`
}
resources.addCfnOutput(export_user_pool_id, "AuthCognitoUserPoolId")
}
AuthでエクスポートしたユーザープールIDを利用してAuthorizerを設定します。
import { AmplifyApiRestResourceStackTemplate } from '@aws-amplify/cli-extensibility-helper';
export function override(resources: AmplifyApiRestResourceStackTemplate) {
const amplify_meta_json = require('amplify-meta.json')
const env_name = amplify_meta_json.providers.awscloudformation.StackName.split("-").slice(-2, -1).pop()
resources.restApi.body = {
...resources.restApi.body,
"securityDefinitions": {
"sigv4": {
"type": "apiKey",
"name": "Authorization",
"in": "header",
"x-amazon-apigateway-authtype": "awsSigv4"
},
"Cognito": {
"type": "apiKey",
"name": "Authorization",
"in": "header",
"x-amazon-apigateway-authtype": "cognito_user_pools",
"x-amazon-apigateway-authorizer": {
"type": "cognito_user_pools",
"providerARNs": [
{
"Fn::Join": [
"",
[
"arn:aws:cognito-idp:",
{
"Ref": "AWS::Region"
},
":",
{
"Ref": "AWS::AccountId"
},
":userpool/",
{
"Fn::ImportValue": `exportUserPoolId-${env_name}`
}
]
]
}
]
}
}
},
}
//Authorizerはリソースの各メソッドに設定する必要がある
let paths = resources.restApi.body.paths
Object.keys(paths).forEach((key) => {
let path = paths[key]["x-amazon-apigateway-any-method"]
path.parameters = [
...path.parameters,
{
name: "Authorization",
in: "header",
required: false,
type: "string"
}
]
path.security = [
{
"Cognito": []
}
]
});
}
まとめ
上記設定でAuthorizerにCognitoを使用することができます。 AmplifyのOverride用ヘルパーの情報が少なく、記載方法にとまどいましたのでどなたかの参考になれば幸いです。
SESからダイアログに経験者転職してみてどう?入社1ヶ月目の中途メンバーが答える!
初めまして!2022年4月に入社しました、佐々木正男(ささきまさお)です。 私は前職では客先常駐型の企業で情シス系インフラエンジニアをしておりました。 昨年12月にダイアログで働く社員さんのご縁もあってダイアログの選考を受け、入社させていただく運びとなりましたので、その過程などを共有できればと思います。 どうぞ、よろしくお願いいたします!
◆入社までの経緯
私は元々プログラミングスクールに通っており、卒業後はSES企業でインフラエンジニアとしてITエンジニアのキャリアをスタートしました。 前職では主にサーバーやネットワークについての業務知識を積ませていただきました。 元々はアプリケーション開発に興味があったのですが、自身で作成したアプリケーションのデプロイ経験を経て、インフラ分野についても最低限の知識をつけておきたいと思い、前職に就職しました。 昨年12月頃、ある程度インフラ系の業務にも慣れ、そろそろ開発にキャリアを変更したいと思い始めたため、周囲の方にも相談し、その中でダイアログのことを紹介していただいてカジュアル面談を受ける運びとなりました。
◆ダイアログの面接フローと感想
カジュアル面談中は今まで受けたカジュアル面談の中で一番丁寧かつカジュアルさを感じました。 雑談のような話しやすい雰囲気を作りつつも、会社紹介のスライドや説明はとても丁寧にされていて、印象が良かったです。 その次の一次選考ではCTOとエンジニアマネージャーとの面接があり、そこではエンジニアとしての姿勢や技術的な質問などがありました。 面接を担当してくださる方は場を和らげようとしてくださっていましたが、私自身は緊張しやすい性格で、面接ということもあって身構えてしまい全くリラックスができませんでした・・・笑 その次にコーディングテストが用意されていました。 要件が提示されるので、その要件を満たすwebアプリケーションを1週間以内に作成するというもので、私はスクールで扱い慣れていたRailsを使うことにしました。 ただバージョンについては、スクールで学習していたRails5系ではなく、今回はその時リリースされたばかりのRails7系を選びました。 非同期処理やリアルタイム画面更新の処理など仕様が変わっているところがあり、苦労しました・・・。 一部要件を満たす事ができない部分がありましたが、結果としては入社後の研修で補えるレベルと判断していただき次の選考に進む事ができました。 次の選考が最終選考となり、代表と採用担当との面接でした。 それまでに適性検査を受け、その結果を確認しながら面接は進み、代表からは会社の経営状況や求める人物像などのお話をいただきました。 その後、ご提示いただいた内定を承諾しました。
◆ダイアログを選んだ理由
カジュアル面談では、他の社員さんの働き方などもお聞きして、一人一人がすごく伸び伸びとされているんだなという印象を受けました。 技術面においてはダイアログではLaravelをメインに扱っており、私自身もスクール卒業後にLaravelを使ったアプリケーションを作っていたので、親和性が高いと感じました。 そのほかにもデバイスに合わせて色々な技術を取り入れており、手を挙げれば色々と挑戦させてもらえる点がとても魅力的に感じました。
◆SESからダイアログに転職してみての違い
SESとの大きな違いは帰属意識にあると思います。 前職では、自身のスキルアップばかりを考えていましたが、ダイアログに入ってからは、会社のことを第一に考えるようになりました。 例えば、自身のスキルアップや新しい技術へのキャッチアップを考えた時に、これは現在や未来のダイアログにとって必要なことか?を考えるようになったり、自分はどのように立ち回ると、会社やチームにいい影響を与えられるか?を常に意識するようになりました。
◆1ヶ月働いてみた感想、研修へのコメント
私の研修はOJT形式でLaravelの改修タスクを課題としてもらっています。 本稼働しているサービスのソースコードをこれまでみた事がなかったので、ファイルの数やコード量に圧倒されました・・・。 個人でLaravelを触っていたとはいえ、規模も全く違うので毎日が勉強になります。 毎日コードを追ったり、ロジックを考えるのに必死ですが、その中で自身の成長も少しずつ感じることができているので、とても充実しています。
◆応募を検討している方へ一言
少しでもご興味があれば、まずはカジュアル面談を受けてみてください! そこで会社の雰囲気やダイアログのことをしてもらえればと思います! 最後まで読んでいただきありがとうございました。
【Salesforce】簡単にできる連動メール設定
概要
Salesforce AppExchangeに公開している自社パッケージにおいて、顧客環境である機能に連動したメール送信を実装したかった。
非常に簡単にノーコードで実装でき、また対応するオブジェクトの情報も取得できたので、ここにまとめる。
手順:準備編

設定>プロセスの自動化>フロー>新規フローを選択。
フローとは、一言でまとめるとSalesforce上の処理同士をノーコードで自動化したり、連動させたりする機能です。

今回の状況の場合 レコードが作成されたときに、作成したことを内容とともに通知 させたかったので、 こちらの「レコードトリガーフロー」を選択しました。
さまざまな条件でトリガーが用意されているので、必要に応じて選択しましょう。
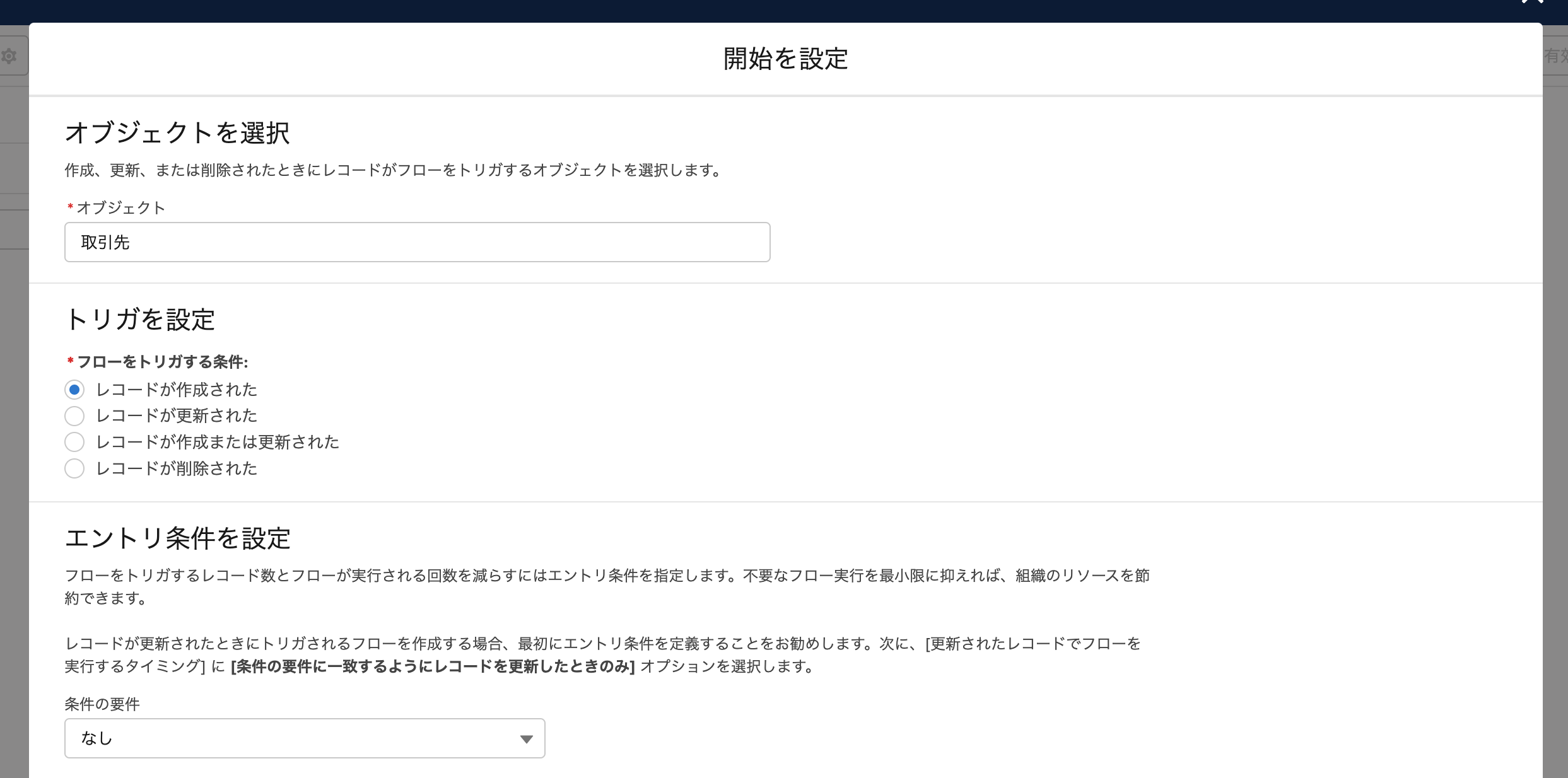
該当のオブジェクトを選択します。今回は例として標準オブジェクトのAccountを選択していますが、もちろんカスタムオブジェクトも可能です。トリガの設定、エントリー(どういう場合のみに適用するか)条件などを決めることができます。
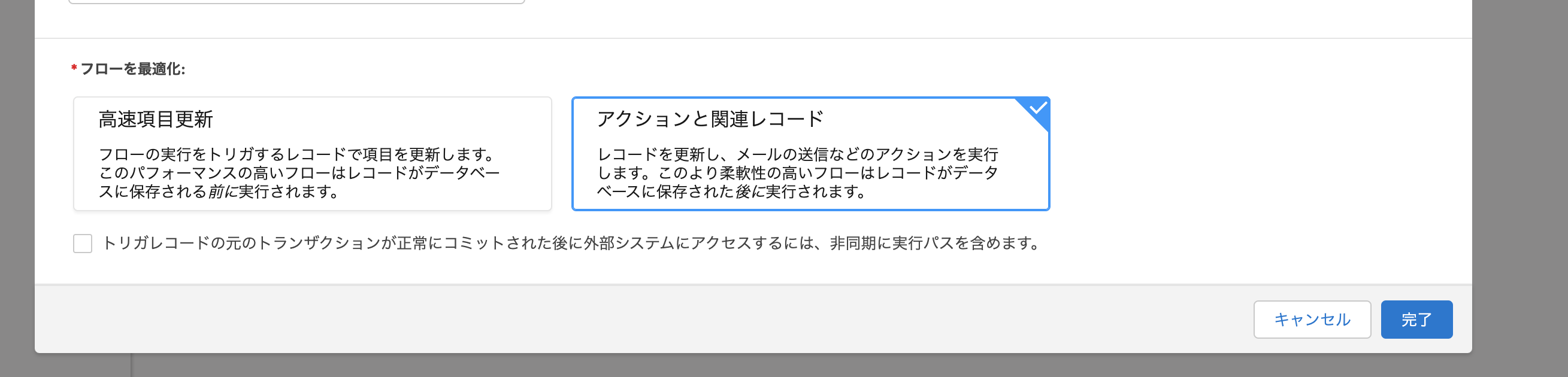
メールを送信する場合は、次の項目は右を選びます。
左に関しては、作成した項目の値で別の値を更新するといった場合に使用できて便利です。 新卒のメンバーのアカウントが作成されたら、従業員名簿に追加するなど(適当です。)
すると、それっぽいものが出来上がります。ここまでで準備はOKです。
手順: 準備後

このような画面になっていると思います。
上の緑の再生ボタンがスタートする地点で、赤の停止ボタンっぽいのが終了です。上から流れるように実行されます。
白い丸のプラスボタンを押してみてください。

以下のように選択肢が出てきますので、メールアラートを送信を押します。
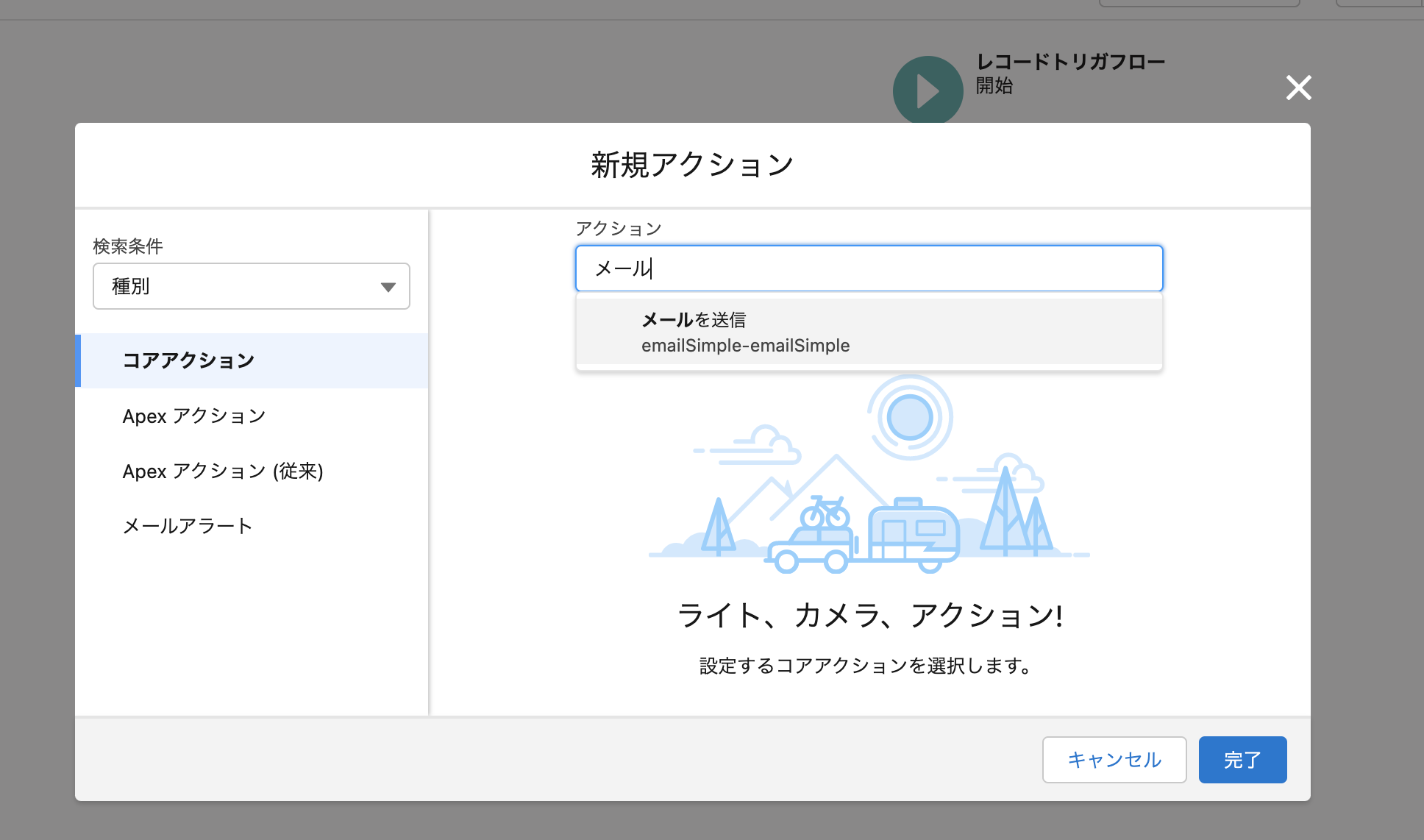
その後、コアアクションを選択し、「メール」と入力するとメールを送信というアクションが出てきますので、押下してください。
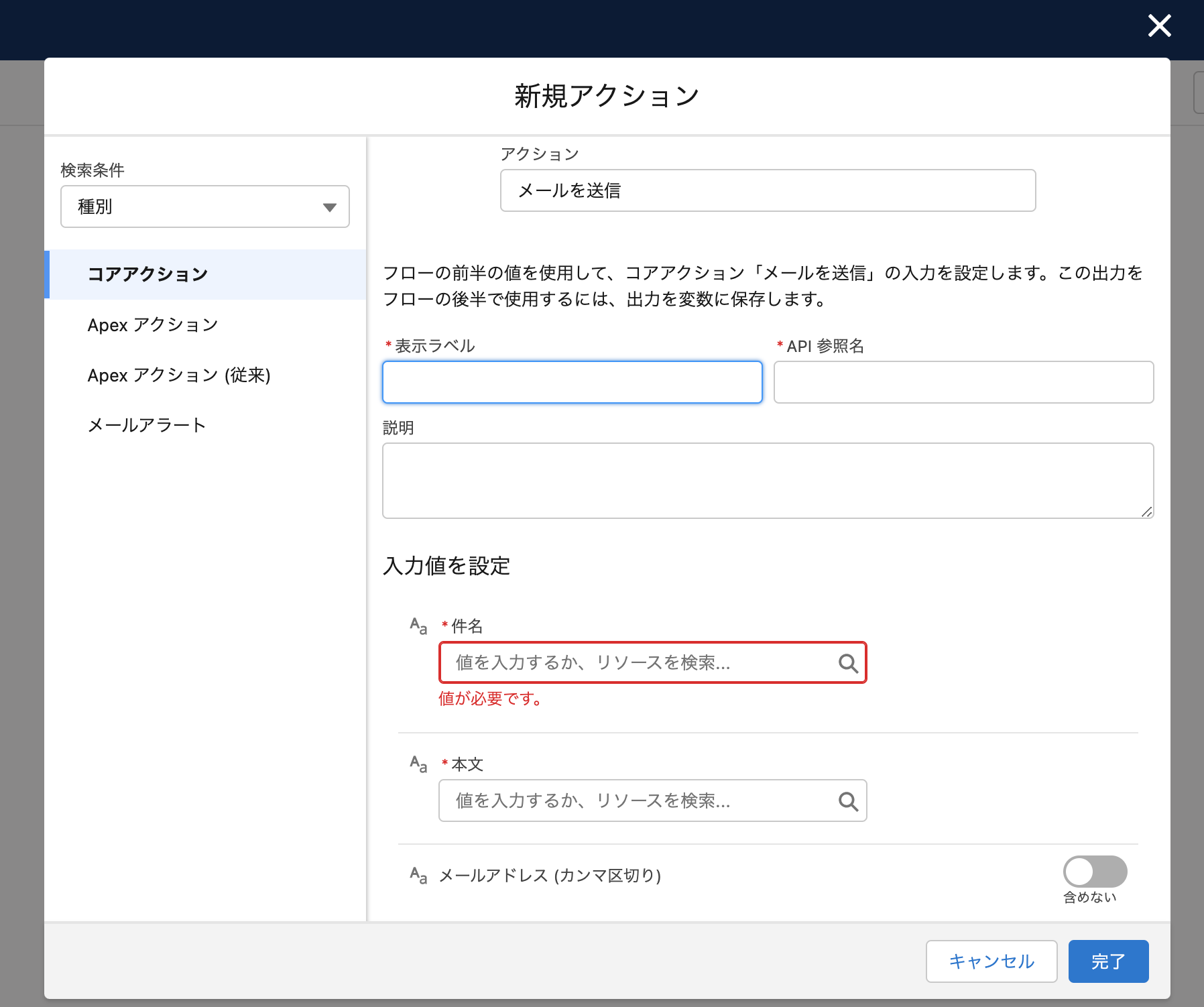
そうすると、なにやら本文などを入力できる場所が出てきました。
表示ラベル、API参照名、説明 これはこのメールを送るアクションのそれぞれの情報です。任意のものを入力してください。
件名、本文、メールアドレス こちらがメールの内容になりますので、送りたい文章と相手を入力してください。リッチテキストなども送れるので、紹介は割愛しますが、その他の項目も是非ご覧ください。
✅ Point
ここがSalesforceのすごいところです。実際にテキスト欄をクリックすると、こんな感じで拡張されます。
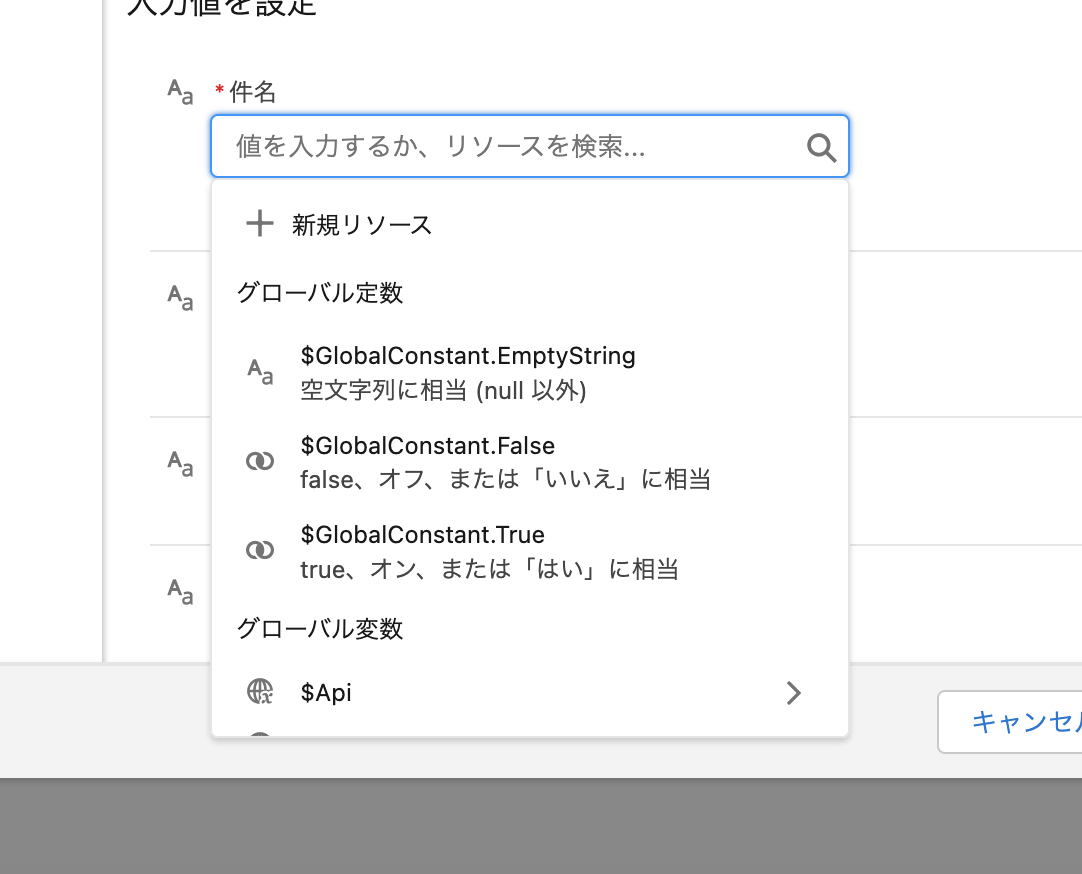
そうなんです。定数や変数を埋め込むことができるんです。
「今フロー中に扱っているオブジェクト」は、ここで設定できます。
つまり、Accountが新規作成されたタイミングで、そのAccount.Nameを取得し ○○さんのアカウントが作成されました!のような件名のメールが送れると言うわけです。
今作成しているレコードは、{!$Record}変数の中に入っています。

それぞれの項目が用意できたら、最後に保存をし、有効化をすることで使用できるようになります。
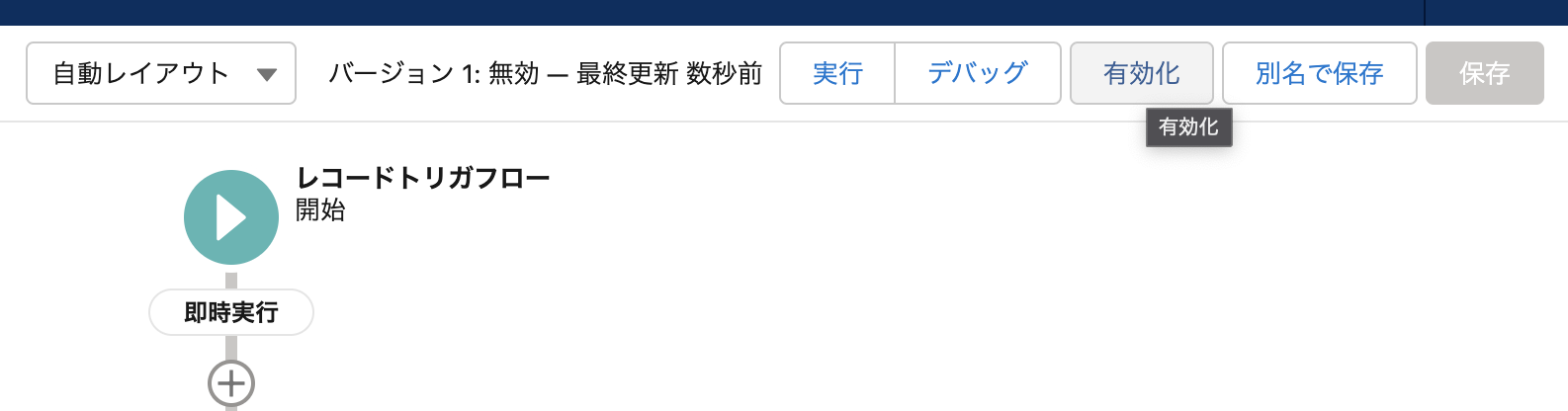
以上です。「もっとこうすると楽だよ!」などご知見をお持ちの方は、是非ご共有くださいませ!
会社の紹介
現在、株式会社ダイアログという物流×ITの会社に勤務しております。
2022年4月現在、エンジニアの募集ページは以下になります。
また、テックブログやTwitterなども運用しているので、是非ご覧ください。
https://twitter.com/dialog_techteam/status/1498184962558017536?s=20&t=XsG7oPbkzI2hxZ4rxbpHaw
Amplifyのoverride.tsで環境名を取得する
課題
Amplify CLIではAuthなどのCFnテンプレートを上書きするためのファイルとして、override.tsが提供されています。このoverride.tsはaws-cdk内の一部のメソッドのみを利用できるようになっています。
本来、getProjectInfo()でAmplifyのプロジェクトの詳細を取得することができるのですが、2022/2/28現在このメソッドはアクセス権限に関する以下のエラーが発生するため利用できません。
⠇ Building resource storage/MyStorage🛑 Error: Skipping override due to VMError: Access denied to require 'os'
override.ts内で環境名を取得する必要がある場合、上記メソッドを使わずに取得する方法をご紹介します。
解決策
※注意 本記事で紹介する解決策は邪道です。issue(https://github.com/aws-amplify/amplify-cli/issues/9063 )が対応され次第修正した方が良いです。
Amplify CLIではプロジェクトの環境等のメタ情報をamplify/backend/amplify-meta.jsonにて保持しています。このファイルはamplify env checkout ...などのコマンドで環境が変更された際、amplify/team-provider-info.jsonの情報を元に構築されるものです。今回はここから環境名を取得します。
手順1:amplify-meta.jsonのモジュール化
amplify-meta.jsonをモジュールとしてシンボリックリンクを貼ります。ファイルを直接読みにいくことも可能のようですが、私の環境ではエラーが発生し読み込めなかったためこの手順を踏んでいます
cd amplify/backend yarn add link:./amplify-meta.json
手順2:override内でStackNameの取得
amplify-meta.jsonのStackNameを取得します。StackNameはamplify-[プロジェクト名]-[環境名]-[プロジェクト番号]で構成されているため、文字列を分解すれば環境名を取得することができます。
export function override(resources: AmplifyAuthCognitoStackTemplate) {
const amplify_meta_json = require('amplify-meta.json')
const env_name = amplify_meta_json.providers.awscloudformation.StackName.split("-").slice(-2, -1).pop()
//省略
}
まとめ
override.ts内で環境名を取得する機会は多いと思われるので、誰かの参考になれば幸いです。 また、この対応はissue内のcespin氏を参考にしております。この場を借りてお礼申し上げます。
参考
株式会社ダイアログで使われている技術をご紹介!Laravel, Salesforce(Apex), AWS...等
ご挨拶
お疲れ様です。エンジニアメンバーのyukiです。 今回は弊社ダイアログで使用されている技術に関してご紹介します!
さまざまな技術に関われるのが弊社の特徴です。 1つでも挑戦したいものがある方は、ぜひ以下の採用ページからご連絡ください。
それでは、プロダクト別にご紹介します。
在庫管理・倉庫管理サービス
主なアプリケーションのバックエンドはLaravelで開発しています。 私も初めて関わった開発がLaravelからのスタートでしたが、クラス設計もわかりやすくて非常に参画しやすかったです。 フロントエンドへのデータを渡す際の開発や、帳票PDFのレイアウト追加など色々な開発を経験できました。
また、AngularJSをReactJSに一部変えていくプロジェクトも走っているので、置き換えに興味がある方にはぜひお力をお借りしたい部分です。
請求書発行サービス
- Salesforce
- Lightning Web Component (LWC)
Apex
開発担当エンジニアからのコメント
SalesforceのAppExchange上で公開しているアプリケーションは、Salesforce社が用意してくださったプラットフォーム上で開発しております。 Apexと呼ばれるJavaをベースにしたバックエンドの言語で、フロントエンドはHTMLとCSSとJavaScriptからなるLWCというSalesforceのフレームワークを使用しています。
※筆者が特にこちらの開発を行なっているのですが、無料の学習ツールも豊富で、Salesforceのコミュニティもたくさんあったりするので学習しやすかったです。
こちらのリンクから学習が行えます。 trailhead.salesforce.com
返品受付サービス
- Laravel
- Vue.js
- Swift
- Firebase
- Flutter
- Amplify
担当エンジニアからのコメント
・AWS関連
インフラには主にAWSを使用しています。 複数インスタンスを立ち上げる規模の大きめなサービスのため、AWSをより活用してみたいエンジニアにとっても良いチャレンジの場です。
また、最近サーバレスな開発の際にAWS Amplifyを選定して開発を進めています。 選定理由としては、元々ある程度の機能があるアプリケーションを応用できそうな開発だったため、せっかくの機会なのでチャレンジしてみました。
少し大変でしたが、こちらに関しては元々社内で使用していなかった技術のため、エンジニア側から提案し実際に使用まで至りました。
・Flutter関連
モバイルアプリケーションの開発もおこなっております。Flutterを採用しており、iosとAndroidともにアプリケーションとして開発しております。 ダイアログでの開発の特徴としては、ハンディターミナルという機械にもAndroidのアプリケーションを入れているため、スマホアプリの開発に加え独自でSDKの開発などが行われています。モバイルエンジニアとしてキャリアを進めたい方にとっても、WEBアプリケーションを開発しつつモバイルに挑戦したい方にとっても、とても良い環境です!
まとめ
いかがでしたでしょうか。ダイアログで使用している技術をまとめてみました。
弊社ダイアログの特徴として、手を挙げれば複数の技術を使用する機会に関われたり、新しい技術の使用を提案したりもしやすい雰囲気があります。 ぜひ積極的にさまざまな技術を取り入れて挑戦したい方は、お気軽にご連絡ください。
Tiwtter始めました!こちらにDMでも大丈夫です。
採用ページ
Flutter ビルド時のエラーの解決策 ( No matching client found for package name)
flutterで、androidのビルド時に下記エラーがでて、詰まったので共有です。
エラー文
Execution failed for task ':app:processDebugGoogleServices'. > No matching client found for package name 'com.xx.xx'
解決策
google-services.jsonのpackage_nameとbuild.gradleのapplicationIdの2つを一致させる必要がありました。
"client": [
{
"client_info": {
"mobilesdk_app_id": "xxxxxxxxxxx",
"android_client_info": {
"package_name": "com.xx.xx" //ここ
}
},
defaultConfig {
applicationId "com.xx.xx" //ここ
minSdkVersion 16
targetSdkVersion 28
versionCode 1
versionName "1.2.2"
multiDexEnabled true
}
参考
最後に
私は現在、株式会社ダイアログという物流×ITの会社に勤務しております。 現在、エンジニアを募集していて、カジュアル面談も実施しているのでお気軽にご連絡ください!
too many placeholders の解消
php/laravelでのクエリ発行はEloquent/Query Builderを使用してDB処理を行うことが多い
と思います。 それを使用するとクエリで使用する文字列をインジェクションができないようにクリーンにすることなくSQLにバインドすることができるので、非常に便利。シンプルなSQLであれば直感的に記述しやすいですね。
使いやすい反面、SQLデータにバインドするデータの量は注意が必要 です。
MySQLのプリペアドSQLで使用できるplaceholderは65,535 (216-1)個までしか使えない
という制約がMySQLにはあります。
制約の数を超えてSQLは実行エラーPrepared statement contains too many placeholderになります。
リストをフィルタしたとの結果に対して全チェックして処理をしたい場合に、対象データの数、更新対象カラムが多いとMySQLを利用したアプリケーションだと対応が必要になります。
今回の事象は一括更新処理にて発生しました。 記述されている処理の内容、対象データとしては下記のような状態でした。
・Modelの中の総カラム数が70で更新対象レコードが3,000件 ・弊社の環境ではModelに拡張してbulkUpdatesのメソッドを追加しています。
$getRecords = Model::whereIn('id', $posted->lists('model_id'))
->lockForUpdate()
->get(); // ・・・ (A)
$bulkUpdateRecords = collect(); // ・・・ (B)
foreach ($getRecords as $getRecord) {
$getRecord->target_column_a = 'aaa';
$getRecord->target_column_b = 'bbb';
$getRecord->target_column_c = 'ccc';
$bulkUpdateRecords->push($getRecord); // ・・・ (C)
}
Model::bulkUpdates($bulkUpdateRecords); // ・・・ (D)
(A) getRecordsにidでデータ取得とともにレコードロックをかけておきます。
(B) 一括更新用データ格納のための変数をcollection()を格納し、初期化します。
(C) 取得したレコードのカラムを更新する値をセットします。今回は三つのカラムに値をセットしています。
(D) 一括更新用データ(bulkUpdateRecords)をモデルに拡張されたメソッドに引き渡し一括更新を行っています。
bulkUpdates内で更新対象データを1,000件ごとにchunkして一括更新を行なっています。
この処理の流れで(D)の段階でPrepared statement contains too many placeholderのエラーがログに出力されました。
取得したレコードはテーブルに存在するカラム全ての値を保持した状態なので1レコード70カラム、更新対象を1,000件毎にchunkして更新ということで70 * 1000 = 70,000のplaceholderを使用したSQLが実行されたことになります。
対応方法
下記2点が考えられると思います。
- chunk数を500などに減らす
- キーカラム+更新対象をbulk処理へ引き渡す
1.の対応方法はchunkの設定を変えるだけなのでお手軽に対応ができます。ただテーブルカラムが増えていくとエラーは再現してしまいます。 2.の対応方法はコードの量は断然増えてしまいますが、テーブルカラム増ではエラーが起きないので、いつかのマイグレーションでここの処理がエラーすることはなくなります。
今回は2.の対応で修正しました。
修正後のコード
$getRecords = Model::whereIn('id', $posted->lists('model_id'))
->lockForUpdate()
->get();
$bulkUpdateRecords = collect();
foreach ($getRecords as $getRecord) {
$update = new Model(); // ・・・ (a)
$update->id = $getRecord->id; // ・・・ (b)
$update->target_column_a = 'aaa';
$update->target_column_b = 'bbb';
$update->target_column_c = 'ccc'; // ・・・ (c)
$bulkUpdateRecords->push($update);
}
Model::bulkUpdates($bulkUpdateRecords);
(a) 更新テーブルのクラスで新しいインスタンスを作成します。
(b) 今回はupdate処理なので新しく作成したインスタンスにidをセットする必要があります。
(c) 新しく作成したインスタンスの更新カラムに値をセットします。
記述は特に難しくなく新しいモデルインスタンスを作成しidをはじめとした必要カラムをセットしてbukl処理にのせるだけです。これでPrepared statement contains too many placeholderの対応は完了です。
ただtoo many placeholderが起きる可能性は至る所にあります。
1.今回のコードの中でもロックの際にwhere inで取得しているところもidが65,535個を超えない保証がない場合、 2.bulkupdateでなく、bulkinsertの処理では基本的には全カラムを指定してクエリを作成しないといけない場面などなど。
selectの場合はBuilderをクローンしてchunkで処理、レコードをマージする、bulkinsertではchunkを調整する、などケースバイケースで対応していくしかないと思います。
MySQL環境でクエリを作成・実行する際にはplaceholderで指定する動的データ数を常に意識して楽しいMySQLライフを送りましょう